Koneoppiminen ja väärien lajitunnistuksien löytäminen
Laji.fi sisältää yli 50 miljoonaa lajihavaintoa, joista useat ovat aktiivisten harrastelijoiden ja kansalaisten keräämiä. Tämä suuri datamassa sisältää lähes varmasti joitain virheellisesti tunnistettuja lajeja, sillä usein lajien tarkka määritys on vielä aika hankalaa, eikä siihen tarvittavaa osaamista tai välineistöä ole jokaisella harrastelijalla. Myöskään ammattilaiset eivät pysty jokaista havaintoa tarkastamaan.
Siispä laadunparantamisen nimissä annotoijien eli havaintojen (usein vapaaehtoisten) tarkastajien työmäärää pitäisi jotenkin helpottaa joko tarkastamalla havainnot automaattisesti tai vähintäänkin rajaamalla tarkistettavien havaintojen määrä pienemmäksi.
Täysin vedenpitävä havaintojen luokittelu oikeaksi/vääräksi on hankalaa jo pelkästään biologian monimutkaisen luonteen vuoksi, mutta jonkinlaista vihiä voi päätellä havainnon sijainnin, päivämäärän ja lajimäärityksen perusteella. Esimerkiksi metsätähti tuskin kukkii tammikuussa Pohjois-Lapissa.
Yksinkertaisimmillaan kaikki uusien eliömaakuntien uudet lajitulokkaat voitaisiin tarkistaa, tai vaikkapa kaikki maalla sijaitsevat vesikasvit. Jos haluaa mennä syvemmälle, voi luoda lajien levinneisyyttä kuvaavan koneoppimismallin allekirjoittaneen tapaan.
Tutkimuskirjallisuutta luettuani tuumailin Random Forestin olevan suosittu malli, johon voi syöttää jokaiseen havaintoon liittyviä havaintoa, ja sen ympäristöä kuvaavia muuttujia. Itse päätin käyttää uudelleen luokiteltua CORINE-aineistoa, sekä keskimääräistä lämpötilaa, sadantaa ja puun tilavuutta kuvaavia rastereita (kuva 1), joita muokkailin hieman malliin sopivaksi mm. normalisoimalla arvot ja interpoloimalla reiät. Näistä rastereista poimin jokaiselle lajihavaintopisteelle sen sijaintia vastaavat arvot.

Kuva 1. Puun tilavuus, keskimääräinen sademäärä ja keskimääräinen lämpötila rasterit visualisoituna.
CORINE-rasterin tapauksessa hyödynsin 100 m bufferia jokaisen pisteen ympärille (kuva 2), josta laskin prosentuaaliset osuudet jokaiselle maankäyttötyypille. Tällä pyrin tasoittamaan CORINEn tarkkarajaista luonnetta erityisesti eri maankäyttötyyppien reunoissa.
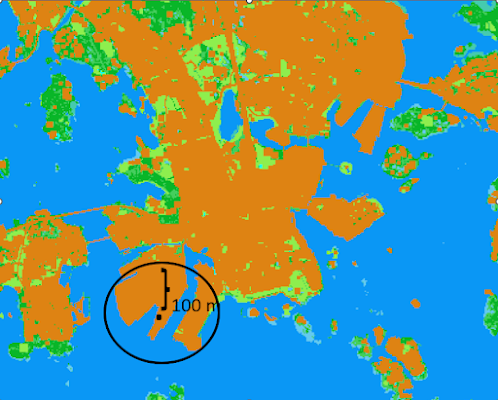
Kuva 2. Uudelleenluokiteltu CORINE-rasteri
Ennen Random Forest malliin syöttämistä yksittäisen pisteen arvot näyttivät siis about tältä:
day_in_year 0.886740
x 0.417161
y 0.053769
Urban 0.000000
Park 0.350000
Rural 0.087500
Forest 0.350000
Open forest 0.165430
Fjell 0.000000
Open area 0.000000
Wetland 0.000000
Open bog 0.107143
Freshwater 0.000000
Marine 0.000000
dem 0.153187
rain 0.943409
temp 0.632882
tree_vol 0.228264
Myös muita muuttujia voisi harkita. Esimerkiksi puun tilavuus tuskin on kovin oleellinen muuttuja kaikille lajeille.
Kouluttamattomat mallit, joita myös testasin, olivat yksinkertaisempia. Niihin pystyi datan heittämään jo tässä vaiheessa ja ne tuottivatkin jonkinlaisia tuloksia. Alla olevissa visualisoinneissa (kuva 3.) sinisellä värillä on visualisoitu mahdolliset outlier-havainnot:

Kuva 3. Kouluttamattomien mallien tuloksia komealupiinille.
Random Forestia varten malli tarvitsee kuitenkin luokiteltua koulutusdataa, joka onkin kinkkisin osuus. Oikeasti luokiteltua dataa vääristä tai ’poissaolevista’ havainnoista ei oikein ole saatavilla, eikä muiden lajien havaintojen hyödyntäminen vertailudatana näyttänyt toimivan. Siispä tein kuten useimmissa tutkimuksissa ja käytin vertailudatana sattumanvaraisia taustapisteitä koko Suomen alueelta. Toki tässäkin menetelmässä on vinoutumia, joita voisi viilata, mutta vähemmän kuin monissa muissa.
Alla kuva komealupiinin oikeista havainnoista (punaisella) ja generoiduista taustahavainnoista (sinisellä).

Kuva 4. Komealupiinin luokittellut oikeat ja taustahavainnot.
Nyt aineisto on siis luokiteltu kahteen luokkaan, ja molemmille luokille laskettu ympäristöä kuvaavat arvot. Toiseksi kinkkisin osuus on datan jakaminen koulutus- ja testidatoihin. Tämä on maantieteellisessä datassa totuttua hankalampaa, koska maantieteellisissä muuttujissa on lähes aina spatiaalista autokorrelaatiota, joka voi vääristää tuloksia.
Yksi keino vähentää spatiaalisen autokorrelaation vaikutusta on jakaa aineisto koulutus- ja testidataan käyttämällä shakkiruutujakoa, kuten alla olevassa kuvassa.

Kuva 5. Data jaoteltu opetus- ja testidataan.
Sen jälkeen datat voi tunkea malliin ja ihmetellä tuloksia vaikkapa kartan muodossa. Alla olevassa kuvassa poikkeavat havainnot ovat sinisellä ja todennäköisemmin oikeat punaisella.

Kuva 6. Random Forestin tuloksia about oletusparametreillä.
Toki tuloksia on lähes mahdoton varmistaa todeksi, kun vertailuaineistoa ei ole. Varmaa kuitenkin on, että malli ennustaa aina outliereitä myös virheettömästä aineistosta.
Malleihin sisältyy muutenkin aina paljon epävarmuuksia, sillä biodiversiteetin monimutkaisuus ei helposti taivu matemaattisiin malleihin. Ehkä tällainen malli voisi kuitenkin auttaa vapaaehtoisia havaintojen tarkastajia löytämään ne havainnot, jotka ovat hieman todennäköisemmin vääriä, kuin oikeita.
GitHub repositorio (ilman rastereita): https://github.com/AlpoTurunen/FinBIF_Outlier_Detection


Kommentit
Lähetä kommentti